Scheduling Model:GCC and LLVM Perspectives
Posts in This Series·
- Understanding In-Order Pipelines and Pipeline Stalls
- What We Need in a Scheduling Model
- Scheduling Model: GCC and LLVM Perspectives
- Tuning Your Scheduling Model for Better Performance(TODO)
A Simple Scheduling Model·
在上一篇中我们提到,如果调度器想要通过指令重排布来解决流水线中的三大问题——发射阻塞、资源冲突以及数据冲突,那么它就需要知道一些流水线的硬件信息。
为了避免发射阻塞,调度器需要知道流水线一次能发射多少条指令,也就是它有多少条发射通路。另外,每条指令可能会被解码成多个微操作,也需要考虑进去。
对应我们结构体中的字段是:
Pipeline.issue_widthIns.num_micro_ops
而要避免资源冲突,调度器需要知道:
- 流水线有哪些功能单元
- 每种功能单元有多少个
- 每条指令会用到哪些功能单元,以及需要使用多久
对应字段是:
Pipeline.func_unitsFuncUnit.num_unitsIns.used_unitIns.taken_cycles
为了解决数据冲突,调度器必须知道,某条指令写入的寄存器,经过多少个周期后才能被其他指令读取
对应:
Ins.latency
我们用三个结构体就能把这些信息抽象得很干净,
1 | struct FuncUnit { |
假设我们有一个双发射(Dual-Issue)流水线,它有以下几种功能单元:
- 2 个 ALU(算术逻辑单元)
- 1 个 LDST(加载/存储单元)
- 1 个 FP(浮点单元,非流水线化)
- 1 个 MUL(乘法单元)
- 1 个 DIV(除法单元,非流水线化)
我们用如下图示意一下,
flowchart LR
%% Issue Paths
Issue0[Slot 0]
Issue1[Slot 1]
%% Connections
Issue0 --> ALU0
Issue0 --> ALU1
Issue0 --> LDST
Issue0 --> MUL
Issue0 --> DIV[Non-Pipelined DIV]
Issue0 --> FP[Non-Pipelined FP]我们可以通过抽象出来的三个结构体,很轻松地描述出这个流水线,
1 | struct FuncUnit ALU = { .num_units = 2 }; |
听起来可能有点不可思议,但这三个结构体,确实可以描述绝大多数流水线架构的调度行为。没错,就是这么简单。
当然,在实际的工程中,比如 LLVM 或 GCC,它们的调度模型肯定比这个复杂得多。毕竟它们要支持所有的指令,并且要融入编译器自身的 IR 和 Pass 架构,以及要使用更通用的建模方式,比如 LLVM 中使用 tablegen 来生成调度模型。
但是万变不离其宗。无论外壳如何复杂,底层所依赖的信息,其实就是我们上面展示的这些。
LLVM Scheduling Model·
LLVM 调度模型的核心定义均位于 llvm/include/llvm/Target/TargetSchedule.td 中,但直接去看这些 tablegen 代码,可能会直接淹死在代码海里,并且其中很多的 class 其实是为了一些特定用途而设计的,使用频率很低,因此我们还是直接看看实际的调度模型代码,看看核心 class 的用法。
FuncUnits description·
llvm/lib/Target/RISCV/RISCVSchedAndes45.td 是上游添加的描述AndesD45流水线的调度模型文件,我们可以从这个文件看看如何使用 LLVM 定义流水线资源的。
源码注释中详细描述了AndesD45流水线的功能单元种类和数量,
1 | //===----------------------------------------------------------------------===// |
如果使用我们定义的结构体,类似如下形式,
1 | struct FuncUnit ALU = { .num_units = 2 }; |
而在 tablegen 中的写法也比较直观,
1 | def Andes45ALU : ProcResource<2>; |
ProcResource 继承自 ProcResourceUnits,本质上和我们定义的 FuncUnit 是一个意思,都表示一种功能单元及其数量,只不过 LLVM 在这个基础上还拓展了更多数据。
在定义 ProcResource 必须要传入一个 int 值去初始化 ProcResourceUnits 中的 NumUnits ,此变量即对应我们定义的结构体中的 FuncUnit->num_units,表示该功能单元的数量。
1 | class ProcResource<int num> : ProcResourceKind, |
可以看出,语言其实只是载体,tablegen 语言只是换了一种表达形式而已,它们承载的核心信息其实是类似的。
当然,ProcResourceUnits不可能只包含一个NumUnits,它还有一些其他的成员变量,
1 | class ProcResourceUnits<ProcResourceKind kind, int num> { |
Kind是功能单元的唯一标识Super表示父功能单元,例如某些子资源的占用同时也会占用上层资源BufferSize表示该资源的保留站大小(对于乱序核来说,通常大于 0)SchedModel指向其所属的调度模型
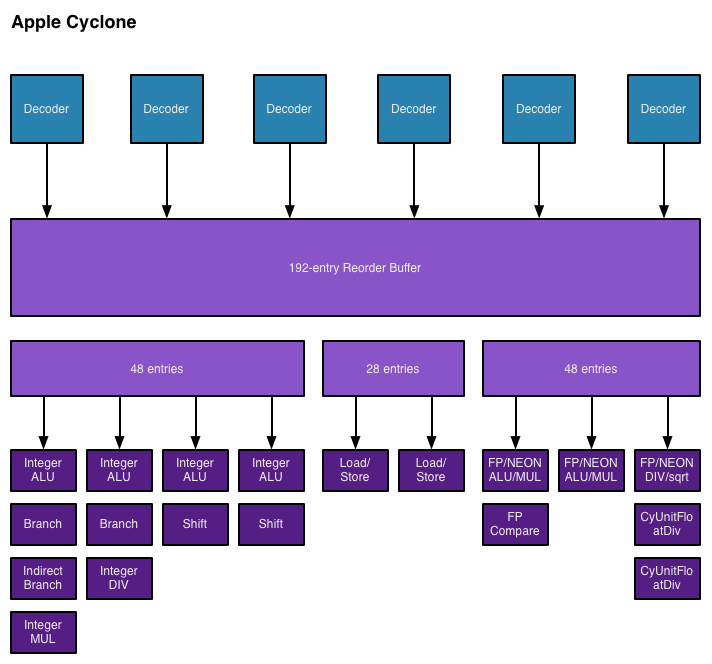
参考 llvm/lib/Target/AArch64/AArch64SchedCyclone.td,Apple Cyclone 的调度模型里定义了一个 CyUnitIS,它是 CyUnitI的子资源。这意味着使用 CyUnitIS 的同时也会占用 CyUnitI。
1 | // 4 integer pipes |
这一设计,在如下图所示的 Apple Cyclone 流水线图中也能看出,此 Pipeline 有四条 Integer ALU 通路,总的 entry 数量为 48,因此 CyUnitI 的 BufferSize 为 48,并且 NumUnits 为 4。而 CyUnitIS 表示两个专门处理移位操作的通路,从图中可以看到,仅有两个,并且当有指令进入 Shift 通路的时候,同一时刻后两个 Integer ALU 通路也应该被占用,通过 Super 可以达到此目的。
Pipeline description·
我们前面定义的 Pipeline 结构体如下,
1 | struct Pipeline Simple_Core = { |
issue_width 表示发射通路数量,func_units 是功能单元集合。
LLVM 中的调度模型定义是通过 SchedMachineModel 进行建模的。我们可以看看 Andes45Model 是如何定义的,
1 | def Andes45Model : SchedMachineModel { |
其中:
IssueWidth:发射宽度,用于告诉调度器每个周期可以发射几条微操作MicroOpBufferSize:与乱序核相关,用于建模统一保留站,0 表示顺序核LoadLatency:load 指令的默认延迟MispredictPenalty:分支预测失败的代价CompleteModel:设为 1 会强制所有指令都必须定义延迟信息,否则报错,适合调试用
MicroOpBufferSize 看起来可能会容易与 ProcResourceUnits 的 BufferSize 混淆,两者其实是为了分别表示 Unified reservation station 和 Decoupled reservation stations,这部分这篇博客有更详细的表述。
LoadLatency 用于对有 mayLoad 属性的指令给定一个默认值作其 Latency。如果没有显式定义一个 mayLoad 指令的 Latency ,则 LoadLatency 会作为其默认值在 TargetInstrInfo::defaultDefLatency 中返回。
1 | /// Return the default expected latency for a def based on it's opcode. |
MispredictPenalty 代表如果发生分支预测失败,大概可能会导致多少个周期的流水线停顿。之前说过,调度器并不关心也无法处理分支预测失败导致的流水线停顿,但是这里为什么会有这个变量呢?这是因为与分支优化相关的 Pass 可能需要这个流水线信息来做对应的优化决策,这个变量是提供给其他和分支优化相关的 Pass 查询使用的, 并不是提供给调度器使用的。
CompleteModel主要可以用来检测调度模型是否定义完整,是否涵盖到所有的指令,如果 CompleteModel 被设置为 1,而有指令未进行 Latency 相关的定义,则会报错。开发者可以利用此来检测是否有指令遗漏了延迟信息等定义。检测的代码如下,
1 | // If DefIdx does not exist in the model (e.g. implicit defs), then return |
父类 SchedMachineModel 中还有一些其他的变量定义,用于一些特殊的用途,就交给读者自己发掘了。
Instruction description·
对于单条指令的调度信息,前面我们用结构体定义了一条 mul 指令的调度信息,
1 | struct Ins MUL_ins = { |
如果在 LLVM 的 tablegen 里建模,写法大致如下:
1 | let NumMicroOps = 1, ReleaseAtCycles = 1, Latency = 3 in { |
这里的 WriteRes 继承自 ProcWriteResources,它的核心作用是描述指令对功能单元的占用情况。参数WriteIMul 是一个 SchedWrite ,参数 [MUL] 表示用到的资源列表。
1 | class WriteRes<SchedWrite write, list<ProcResourceKind> resources> |
它们和我们前面结构体的字段一一对应,
| 结构体字段 | TableGen 字段 | 含义 |
|---|---|---|
| num_micro_ops | NumMicroOps | 微操作数量 |
| used_unit | ProcResources | 哪些资源被使用 |
| taken_cycles | ReleaseAtCycles | 使用该资源多少个周期 |
| latency | Latency | 等待多少周期可用 |
SchedWrite and SchedRead·
在 LLVM 的调度模型中,每条汇编指令在定义时,会将目的寄存器和源寄存器分别绑定到 SchedWrite 和 SchedRead。这样,调度器可以分别对每个操作数的资源占用和延迟进行精细建模。
以 mul reg0, reg1, reg2 为例:
reg0是目的寄存器,对应一个 SchedWrite(如 WriteIMul)reg1、reg2是源寄存器,对应两个 SchedRead(如 ReadIMul)
TableGen 里的定义大致如下:
1 | def MUL : ALU_rr<0b0000001, 0b000, "mul", Commutable=1>, |
同理,add 指令也会有自己的 SchedWrite/SchedRead 绑定和资源建模,
1 | def ADD : ALU_rr<0b0000000, 0b000, "add", Commutable=1>, |
通过这种方式,调度器可以在构建依赖图时,精确知道每个 SchedWrite 资源占用和延迟信息。而 SchedRead 另有它用。
ReadAdvance·
实际硬件中,某些数据依赖可以通过旁路(forwarding)机制提前满足,而不必等到写操作的全部延迟周期结束。LLVM 用 ReadAdvance 来描述这种"提前读取"的能力。
ReadAdvance 的作用是:
- 指定某个 SchedRead 对某个 SchedWrite 的依赖延迟可以减少多少周期
- 这样可以精确建模数据前推、旁路等微架构优化
假设有如下指令序列:
1 | mul a0, a2, a3 |
如果 mul 的 Latency = 3,且没有前推,则 add 需要等待 3 个周期:
graph TD
MUL[mul a0, a2, a3]
ADD[add a1, a0, a4]
MUL -- "RAW: Latency = 3" --> ADD假设硬件支持前推,add 读取 mul 的结果时可以提前 1 个周期(ReadAdvance = 1),则只需等待 2 个周期:
1 | def : ReadAdvance<ReadIALU, 1, [WriteIMul]>; // add 读取 mul 的结果可提前 1 个周期 |
graph TD
MUL[mul a0, a2, a3]
ADD[add a1, a0, a4]
MUL -- "RAW: Latency = 2 (forward)" --> ADD再看另一组指令:
1 | add a0, a2, a3 |
假设 add 的 Latency = 1,mul 没有前推,则 mul 需要等待 1 个周期:
graph TD
ADD[add a0, a2, a3]
MUL[mul a1, a0, a4]
ADD -- "RAW: Latency = 1" --> MUL如果 mul 读取 add 的结果也支持前推(ReadAdvance = 1),则可以实现 0 周期依赖:
1 | def : ReadAdvance<ReadIMul, 1, [WriteIALU]>; // mul 读取 add 的结果可提前 1 个周期 |
graph TD
ADD[add a0, a2, a3]
MUL[mul a1, a0, a4]
ADD -- "RAW: Latency = 0 (forward)" --> MUL有了 ReadAdvance,调度器就可以灵活地表达不同指令对之间的真实依赖延迟了。
Summary·
至此,LLVM 调度模型的核心建模思路已经完整梳理。对于一个典型的顺序核流水线,调度模型的编写流程可以总结为:
- 定义资源(功能单元)
- 使用
ProcResource描述流水线中各类功能单元及其数量。
- 使用
- 定义调度模型(SchedMachineModel)
- 指定发射宽度、默认延迟等。
- 为每类 SchedWrite 绑定资源和延迟(WriteRes)
- 明确每种写操作对资源的占用和延迟。
- 通过 SchedRead/ReadAdvance 精细建模数据依赖
- 用
ReadAdvance灵活修正不同指令对之间的实际依赖延迟,准确反映硬件的旁路能力。
- 用
顺序核和乱序核的主要区别在于是否需要建模保留站(BufferSize),流水线资源、延迟、数据依赖的建模方式是通用的。因此只要掌握了上述流程,结合实际硬件流水线图和白皮书文档,就可以高效地为自己的目标架构编写出准确的 LLVM 调度模型。
GCC Scheduling Model·
由于我没有完整写过 GCC 的调度模型文件,不了解其完整的框架,只是阅读过其调度模型文件,这里主要介绍 GCC 调度模型部分基础语法和与 LLVM 的语法进行对比,不详细解释其中的细节了,没有提到的以及具体语法细节也可以看官方文档。
FuncUnits description·
GCC 使用 define_automaton 定义自动机,再用 define_cpu_unit 绑定功能单元,
1 | (define_automaton "core") |
define_automaton声明一个自动机define_cpu_unit声明一个或多个功能单元,并绑定到自动机
这和 LLVM 的 ProcResource 类似。这样就定义了四个功能单元,并且它们的数量都为 1。这里需要注意的是,GCC 并没有提供定义多个相同功能单元的语法,也就是说,如果需要定义两个 alu,可以定义成 alu0 和 alu1。
并且,GCC 的调度模型也不包含单独的 issue_width 变量定义,我们在之前说过,发射通路本质也是一种资源,GCC 可以直接使用 define_cpu_unit 来定义。
1 | (define_cpu_unit "pipe0" "core") |
Instruction description·
GCC 用 define_insn_reservation 描述每类指令的延迟和资源占用,
1 | (define_insn_reservation "alu_insn" 1 |
alu_insn是 define_insn_reservation 的名字1是该类型指令的 latencyand是过滤条件,这里筛选了core架构下的shift,nop,logical指令pipe0+alu0 | pipe1+alu1是资源占用描述
这里的意思是移位运算,逻辑运算,以及nop的 latency 均为 1,并且第一个周期占用 pipe0+alu0 或者 pipe1+alu1。
这和 LLVM 的 WriteRes 用途类似。
资源占用描述也可以更复杂一点,如下表示 core 架构下的 imul 指令 latency 均为 3,第一个周期占用 pipe0+alu0 或者 pipe1+alu1,第二个和第三个周期占用 mul 单元。
1 | (define_insn_reservation "mul_insn" 3 |
Forwarding description·
GCC 用 define_bypass 显式描述不同指令对之间的旁路(bypass),即某些指令对的依赖延迟可以异于默认值,
1 | (define_bypass 1 "mul_insn" "alu_insn") |
- 表示
alu_insn读取mul_insn结果时,延迟为 1,而不是默认 3
这和 LLVM 的 ReadAdvance 有些差别。def : ReadAdvance<ReadIALU, 1, [WriteIMul]> 含义是,alu 指令读取 mul 的结果可提前 1 个周期,而 GCC 中的表示延迟就是 1 个周期。