In-Order Pipeline and Pipeline Stalls
Posts in This Series·
- Understanding In-Order Pipelines and Pipeline Stalls
- What We Need in a Scheduling Model
- Scheduling Model: GCC and LLVM Perspectives
- Tuning Your Scheduling Model for Better Performance(TODO)
Extended in-order pipeline·
Extended EX stage pipeline·
我不想在这里讨论基本的五级顺序流水线概念,你可以在任何一本介绍计算机体系结构的书上找到相关的内容,所以我会假设你已经了解基本的顺序流水线知识、流水线冒险(结构冒险、数据冒险、控制冒险)、数据前推,如果你对提到的任何关键词有疑问,请先补充相关的知识 😉
flowchart LR
IF[IF]
ID[ID]
EX[EX]
MEM[MEM]
WB[WB]
IF --> ID
ID --> EX
EX --> MEM
MEM --> WB如上图,基本的五级流水线(取指,译码,执行,访存,写回)由于做了简化,并没有暴露其中的细节。从图中看起来所有的执行单元被抽象成一个 EX stage,而真实的 CPU 流水线不仅要处理基本的整数运算,还需要处理浮点运算以及它们各自的加减乘除,所以一个完整的 EX stage 至少会包括 ALU 单元运算,乘法除法器运算单元,浮点加减运算单元,浮点乘除运算单元。
假设我们有一个可以处理各种整数运算,浮点加减乘除运算的流水线,从黑盒子的角度来看,它可能长成下图这个样子。
flowchart LR
IF[IF]
ID[ID]
INT_OP[Integer Unit]
FP_ADD[FP Add/Sub]
FP_MUL[FP Mul]
FP_DIV[FP DIV]
MUL[MUL/DIV]
MEM[MEM]
WB[WB]
IF -->| | ID
ID -->| | MUL
ID -->| | FP_DIV
ID -->| | INT_OP
ID -->| | FP_ADD
ID -->| | FP_MUL
MUL -->| | MEM
INT_OP -->| | MEM
FP_ADD -->| | MEM
FP_MUL -->| | MEM
FP_DIV -->| | MEM
MEM -->| | WB不同硬件实现不同,可能有些流水线会把一些功能单元做合并或拆分,比如将 MUL 和 DIV 分开,分别负责整数乘法和除法。
假设我们现在有这样一段汇编代码,
1 | add a0, a1 --> integer unit |
当每条指令走过 ID 阶段以后,会进入各自的功能单元执行,互不干扰。
Pipelined or Not-Pipelined·
像大部分简单的 ALU 指令,比如加减法指令,通常只需要一个周期就能够完成,但由于存在长周期指令,比如,乘法指令,除法指令,由于其本身硬件实现的复杂性,所以基本上不可能一个在周期内完成(除非你压缩 CPU 的频率,让其一个周期的时间变长,但这没有意义),所以实际上每个功能单元占用的周期数是不同的。
假设下面列举的流水线都是单发流水线,并且我们所有的功能单元同一时间只能执行一条指令,也就是说,同一周期,当进入一条指令以后,就不能再进入第二条使用相同功能单元的指令了。当出现如下顺序的汇编时,
1 | mul a0, a1 |
如果 mul 指令不能在一个周期完成执行,下一条 mul 就会进入在 MUL/DIV 功能单元之前被阻塞住,也就是出现了流水线暂停的行为。
上述对 MUL/DIV 功能单元的描述,意思就是说,这个功能单元是非流水线化的(Not-Pipelined)。
显然这种流水线是非常慢的,会出现大量因为功能单元被占用导致的流水线暂停,所以这里我们可以引入流水线化(Pipelined)的功能单元来进行加速,允许多个需要同一功能单元的指令同时进行。
flowchart LR
IF[IF]
ID[ID]
INT_OP[Integer Unit]
FP_ADD0[FP Add/Sub Stage 0]
FP_ADD1[FP Add/Sub Stage 1]
FP_ADD2[FP Add/Sub Stage 2]
FP_MUL0[FP Mul Stage 0]
FP_MUL1[FP Mul Stage 1]
FP_MUL2[FP Mul Stage 2]
FP_MUL3[FP Mul Stage 3]
FP_DIV[FP DIV]
MUL0[MUL/DIV Stage 0]
MUL1[MUL/DIV Stage 1]
MUL2[MUL/DIV Stage 2]
MEM[MEM]
WB[WB]
IF -->| | ID
ID -->| | MUL0
ID -->| | FP_DIV
ID -->| | INT_OP
ID -->| | FP_ADD0
ID -->| | FP_MUL0
INT_OP -->| | MEM
MUL2 -->| | MEM
FP_ADD2 -->| | MEM
FP_MUL3 -->| | MEM
FP_DIV -->| | MEM
MEM -->| | WB
MUL0 --> MUL1
MUL1 --> MUL2
FP_ADD0 --> FP_ADD1
FP_ADD1 --> FP_ADD2
FP_MUL0 --> FP_MUL1
FP_MUL1 --> FP_MUL2
FP_MUL2 --> FP_MUL3为了解决上述性能瓶颈,我们将 MUL/DIV 单元流水线化至三级:
- Stage 0:对操作数进行部分积预处理;
- Stage 1:计算部分积;
- Stage 2:生成最终结果并写入目标寄存器。
这里只是举个例子,真实的情况大概率与我所说的不同,这里只是帮助理解如何进行功能单元的流水线化,具体乘法器到底是如何实现,要去阅读相关资料。
在满载状态下,该流水线每个周期可以接受一条新的乘除法指令。虽然每条指令仍然需要 3 个周期才能完成,但由于各阶段可并发运行,总体吞吐率显著提升。
在图中,FP Mul 单元,Mul/Div 单元以及 FP Add/Sub 单元均已被流水线化,该流水线可以同时执行四条浮点乘法指令,三条整数乘除法指令,三条浮点加减法指令,而 FP DIV由于没有流水线化,同一时刻只能有一条指令位于该功能单元内。
这里
Integer Unit也是流水线化的,因为本身就用于执行单周期指令。
当再次出现如下顺序的汇编时,流水线将不会因为资源占用导致暂停了。
1 | mul a0, a1 |
- 大部分功能单元都是流水线化的,但是像
FP Div这种使用频率很少的功能单元,即使做成非流水线化,通常情况下很少会导致流水线暂停。(本身使用FP Div功能单元的指令就比较少,就算出现了多条使用该功能单元的指令,调度器也不会将它们排在一起。)因此,将使用频率很少的功能单元做成非流水线化的,不仅可以减少芯片流水线复杂度,也不会有明显的负面影响。- 这里把功能单元拆成多个 stages 是为了帮助理解,实际的流水线图不会这么画,一个功能单元是否是流水线化的也需要参考对应的白皮书文档。(很多流水线的实际信息都是需要从白皮书中获取的。)
Real Pipeline·
让我们来看一个真实的流水线图,这是晶心科技 Andes-D45 的流水线图。

对应的流水线简化图如下,
flowchart LR
%% Issue Paths
Issue0[Slot 0]
Issue1[Slot 1]
%% Pipelines
ALU0[ALU0]
ALU1[ALU1]
LDST[AGU + LD/ST]
FP[FP Pipeline]
MULDIV[MUL/DIV Pipeline]
DSP[DSP Pipeline]
%% Connections
Issue0 --> ALU0
Issue0 --> ALU1
Issue0 --> LDST
Issue0 --> FP
Issue0 --> MULDIV
Issue0 --> DSPD45 由于是双发的流水线,一个周期会发射两条指令,考虑到 ALU 指令是最频繁的,为了可以同时双发两条 ALU 指令,它这里设置了两条 ALU 通路,也就是说,当出现下面两条汇编指令同时发射时,它们可以分别占用两条 ALU 通路,而不会导致流水线暂停。(可以想到,如果只有一条 ALU 通路的话,那么这里两条 add 指令就没法同时发射了,因为会有资源冲突,流水线会暂停。)
1 | add a0, a1 --> slot 0 -- use ALU0 |
D45 的流水线是非常简单的,没有什么过多需要描述的地方。
- D45 的 ALU 还有一个特殊的地方,它将 ALU stages 划分为两个 stages,EX stage 和 LX stage(L 意味着 Later),这里设计的意图,可能是为了减少数据冲突导致的暂停。这个并不是主要要讨论的问题。
- DSP 单元是为了执行 Andes RISCV-P Extension 的特殊指令。
另一个是 Sifive-P670 的流水线,它是一个乱序 4 发射的流水线,看起来可能稍微复杂一点,
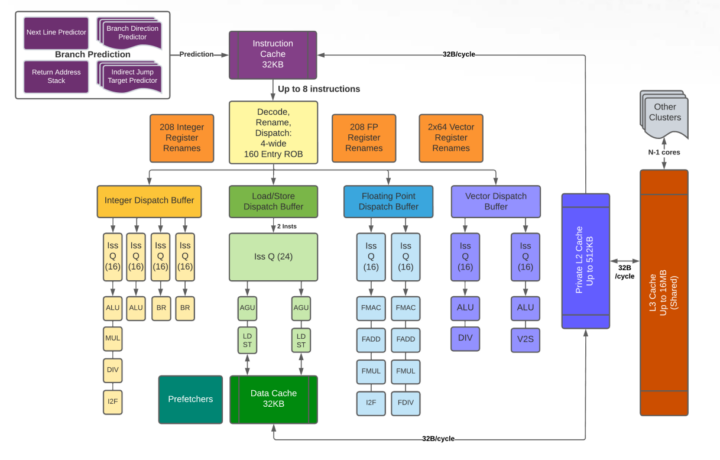
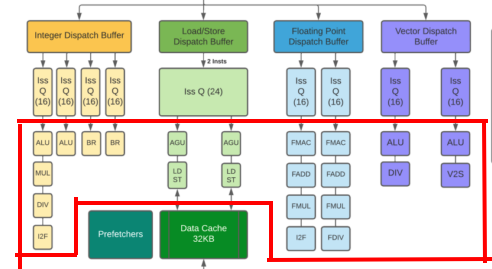
对应的流水线简化图,可以表示成如下形式,
flowchart LR
%% Issue paths
Issue0[Slot 0]
Issue1[Slot 1]
Issue2[Slot 2]
Issue3[Slot 3]
%% ALU Pipelines
ALU_FULL[ALU0: ALU + MUL + DIV + I2F]
ALU_ONLY[ALU1: ALU]
BR0[BR0: BR]
BR1[BR1: BR]
%% LD/SD Pipelines
LDST0[LD/ST0: AGU + LD/ST]
LDST1[LD/ST1: AGU + LD/ST]
%% FP Pipelines
FP0[FP0: FMAC + FADD + FMUL + I2F]
FP1[FP1: FMAC + FADD + FMUL + FDIV]
%% Vector Pipelines
VEC0[Vector0: ALU + DIV]
VEC1[Vector1: ALU + V2S]
%% Connections from Issue paths
Issue0 --> ALU_FULL
Issue0 --> ALU_ONLY
Issue0 --> BR0
Issue0 --> BR1
Issue0 --> LDST0
Issue0 --> LDST1
Issue0 --> FP0
Issue0 --> FP1
Issue0 --> VEC0
Issue0 --> VEC1如果我们把它当做一个四发射顺序核来看的话,这个流水线在遇到如下汇编的时候,
1 | mul a1, a1, a2 --> solt0 -- use the ALU0 pipe |
Pipeline Stalls·
本文前面说了这么多,就是为了铺垫这个东西 😉
我们这里暂时不考虑乱序核的情况,先理解顺序核中的性能损失情况,在此基础上再去理解乱序核会更好。
Types of stall·
现代 CPU 可能因为各种各样的原因导致流水线性能损失,
比如 iCache miss 会导致取指阶段无法及时取到下一条指令,流水线前端得不到新指令,流水线只能空转等待,从而引发性能损失。而即使取到了指令,如果一条指令在解码后被翻译成多个微操作(micro-ops),而流水线的发射宽度(Issue width)不匹配时,需要多个周期才能完成当前所有微操作的发射,前端流水线同样会暂停。
这些性能损失的根源都是因为前端流水线无法持续、稳定地提供指令给后端,通常被统称为流水线前端暂停。
这种由于微操作数量与发射宽度不匹配导致的流水线前端暂停(后面称之为发射阻塞),在 CISC 指令集中(如 x86)中较为常见,而 RISC 指令通常结构比较简单,一条汇编对应一到两个微操作,通常不会发生这种问题。
又比如,当流水线中同时出现两条指令,它们需要相同的功能单元,而这条流水线只有一个该功能单元时,会发生结构冲突或资源冲突,流水线必须暂停等待上一条指令释放该资源。
在 Andes-D45 流水线中,
flowchart LR
%% Issue Paths
Issue0[Slot 0]
Issue1[Slot 1]
%% Pipelines
ALU0[ALU0]
ALU1[ALU1]
LDST[AGU + LD/ST]
FP[FP Pipeline]
MULDIV[MUL/DIV Pipeline]
DSP[DSP Pipeline]
%% Connections
Issue0 --> ALU0
Issue0 --> ALU1
Issue0 --> LDST
Issue0 --> FP
Issue0 --> MULDIV
Issue0 --> DSP假如出现以下汇编,则由于乘法单元只有一个,同时双发两条 mul指令必然会导致流水线暂停,
1 | mul a0, a1, a2 --> slot 0 -- use the MUL/DIV pipe |
进一步再看如下汇编,显然,这对汇编不会发生资源冲突,一个进入 MUL/DIV功能单元执行乘法运算,一个进入ALU功能单元执行加法指令,非常和谐。
1 | mul a0, a1, a2 --> slot 0 -- write `a0`, assuming it can be read after 2 cycles. |
但是不和谐的地方在于,第二条add指令使用了前一条mul指令要写的值,这就是另一中很常见的冲突 – 数据冲突,数据冲突通常分为三类,写后读,读后写,写后写,对应数据依赖(True Dependency/Data Dependency),反依赖(Anti-Dependency),输出依赖(Output-Dependency),具体定义不在这里赘述。
上述由于冲突导致的流水线损失,通常表现为流水线完全暂停等待冲突解除,被称为流水线后端暂停。
What can be solved by the scheduler?·
既然本系列是介绍调度模型的,自然需要知道,调度器是用来解决哪些流水线暂停问题的。
调度器的主要作用,是在代码局部,通常是在一个基本块内,进行指令重排布。它会在不影响代码逻辑正确性的情况下尽可能的减少可能的流水线暂停。所以这个问题就是,对指令进行重排布,可以解决掉哪些可能的流水线暂停?
其实答案就是上节提到的几个流水线暂停的类型: 发射阻塞导致的前端流水线暂停,以及资源冲突,数据冲突导致的后端流水线暂停。
发射阻塞,其实本质上也是一种资源冲突,相当于多个微操作在争夺比它们数量少的发射通路。但是这里分开来看会更好理解一些。
flowchart LR
%% Issue Paths
Issue0[Slot 0]
Issue1[Slot 1]
%% Pipelines
ALU0[ALU0]
ALU1[ALU1]
LDST[AGU + LD/ST]
FP[FP Pipeline]
MULDIV[MUL/DIV Pipeline]
DSP[DSP Pipeline]
%% Connections
Issue0 --> ALU0
Issue0 --> ALU1
Issue0 --> LDST
Issue0 --> FP
Issue0 --> MULDIV
Issue0 --> DSP还是以 D45 流水线举例,假设遇到如下汇编,流水线会如何执行?
1 | mul a0, a1, a2 |
首先,两条mul指令是不能双发的,因为它们同时需要使用 MUL/DIV 单元,所以第一个周期,它只能发射一条mul指令,第二条mul指令需要等到下一个周期才能发射。
当两条mul发射以后,add t0, a0, a3由于与前两条mul都有数据依赖,假设mul发射以后 3 个周期,add指令才能读取这个操作数,则add t0, a0, a3需要停顿 3 个周期才能发射。而第 5 个周期,由于add t0, a0, a3和 add t0, t2, 1它们之间有输出依赖,仍然无法双发。
1 | -- cycle1 -- |
让我们手动调度一下这个汇编代码,
1 | mul a0, a1, a2 |
在两条mul指令之间,插入一条add t1, t1, 1,消除了资源冲突导致的流水线暂停。在存在数据依赖的mul和add之间,插入一条add t3, t3, 1,虽然没有完全消除数据依赖导致的流水线暂停,但是相同的周期数内执行的指令数更多了。在存在输出依赖的两条add之间,插入一条add a0, a0, 1,消除了输出依赖导致的流水线暂停。
1 | -- cycle1 -- |
总结来说,调度器通过重新排布指令的执行顺序,来缓解如下几类性能瓶颈:
- 发射阻塞:例如某些复杂指令被翻译为多个微操作,无法在一个周期完成发射
- 结构冲突 / 资源冲突:多条指令竞争同一个功能单元
- 数据冲突:典型如写后读(RAW)依赖引起的等待
而一些系统性延迟,如 Cache Miss(iCache 或 dCache)、分支预测失败等,通常不是调度器能直接解决的,这类 暂停更多依赖于体系结构本身的优化策略或预取机制。当前,编译器也有比如基本块重排布优化(BasicBlockPlacement),来解决分支预测问题。
所以,调度器并不能解决所有类型的流水线暂停,但它在提升执行单元利用率、隐藏延迟、减少流水线空泡等方面是至关重要的。理解这一点,是编写调度模型之前必须要建立的认知基础。
References·
- 计算机体系结构:量化研究方法(第6版)附录 C
- What are Front-End Stalls and Back-End Stalls ? – from stackoverflow